
Gradient — Gradient

W wektorze rachunku The gradientu z skalarnej wartościach funkcji różniczkowalną f od wielu zmiennych jest pole wektorowe (lub funkcja wektorowa ) , którego wartość w punkcie, jest wektor , których składniki są pochodnymi cząstkowymi z co . Czyli dla , jego gradient jest zdefiniowany w punkcie w przestrzeni n- wymiarowej jako wektor:







Symbolu nabla , zapisanych w postaci trójkąta odwróconej i nazywana „del” oznacza operator różnicowy wektor .

Wektor gradientu można interpretować jako „kierunek i tempo najszybszego wzrostu”. Jeżeli gradient funkcji jest niezerowy w punkcie p , kierunek gradientu jest kierunkiem, w którym funkcja rośnie najszybciej od p , a wielkość gradientu to tempo wzrostu w tym kierunku, największe bezwzględna pochodna kierunkowa. Ponadto gradient jest wektorem zerowym w punkcie wtedy i tylko wtedy, gdy jest to punkt stacjonarny (gdzie znika pochodna). Gradient odgrywa zatem fundamentalną rolę w teorii optymalizacji , gdzie jest używany do maksymalizacji funkcji przez wznoszenie gradientu .
Gradient jest podwójny do całkowitej pochodnej : wartość gradientu w punkcie jest wektorem stycznym – wektorem w każdym punkcie; natomiast wartością pochodnej w punkcie jest wektor co tangens – funkcja liniowa na wektorach. Są one związane z tym, że punkt produkt z gradientem F w punkcie P z innym styczna wektora V równa się kierunkowe pochodną o f w p funkcji wzdłuż v ; czyli . Gradient dopuszcza wiele uogólnień do bardziej ogólnych funkcji na rozmaitościach ; patrz § Uogólnienia .


Motywacja
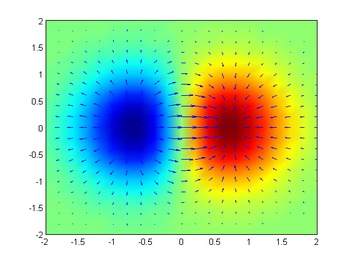
Rozważmy pomieszczenia, w którym temperatura jest podana przez skalarne dziedzinie , T , aby w każdym punkcie ( x , y , oo ) temperatura T ( x , y , z ) , niezależnie od czasu. W każdym punkcie pomieszczenia gradient T w tym punkcie pokaże kierunek, w którym temperatura rośnie najszybciej, oddalając się od ( x , y , z ) . Wielkość gradientu określi, jak szybko temperatura wzrasta w tym kierunku.
Rozważmy powierzchnię, której wysokość nad poziomem morza w punkcie ( x , y ) wynosi H ( x , y ) . Gradient H w punkcie jest wektorem płaskim wskazującym w kierunku najbardziej stromego nachylenia lub nachylenia w tym punkcie. Nachylenie zbocza w tym punkcie jest określone przez wielkość wektora gradientu.
Gradientu można również użyć do pomiaru zmian pola skalarnego w innych kierunkach, a nie tylko w kierunku największej zmiany, przyjmując iloczyn skalarny . Załóżmy, że najbardziej strome nachylenie na wzgórzu wynosi 40%. Droga prowadząca bezpośrednio pod górę ma nachylenie 40%, ale droga okrążająca wzgórze pod kątem będzie miała nachylenie płytsze. Na przykład, jeśli droga jest pod kątem 60° od kierunku pod górę (gdy oba kierunki są rzutowane na płaszczyznę poziomą), wówczas nachylenie wzdłuż drogi będzie iloczynem skalarnym między wektorem gradientu a wektorem jednostkowym wzdłuż drogi , czyli 40% razy cosinus 60°, czyli 20%.
Mówiąc ogólnie, jeśli funkcja wysokość wzgórza H jest różniczkowalną , następnie gradient H przerywana z wektor jednostkowy daje nachylenie Hill w kierunku wektorze kierunkowego pochodnej o H wzdłuż wektora jednostkowego.
Notacja
Gradient funkcji w punkcie jest zwykle zapisywany jako . Może być również oznaczony dowolnym z poniższych:


- : aby podkreślić wektorowy charakter wyniku.
- grad f
- oraz : notacja Einsteina .





Definicja

Gradient (lub gradientowe pole wektorowe) funkcji skalarnej f ( x 1 , x 2 , x 3 , …, x n ) jest oznaczony ∇ f lub ∇ → f gdzie ∇ ( nabla ) oznacza wektorowy operator różniczkowy , del . Notacja grad f jest również powszechnie używana do reprezentowania gradientu. Gradient f jest zdefiniowany jako unikalne pole wektorowe, którego iloczyn skalarny z dowolnym wektorem v w każdym punkcie x jest pochodną kierunkową f wzdłuż v . To jest,

Formalnie gradient jest podwójny do pochodnej; zobacz związek z pochodną .
Gdy funkcja zależy również od parametru, takiego jak czas, gradient często odnosi się po prostu do wektora jej pochodnych przestrzennych (patrz Gradient przestrzenny ).
Wielkość i kierunek wektora gradientu są niezależne od reprezentacji poszczególnych współrzędnych .
współrzędne kartezjańskie
W trójwymiarowym kartezjańskim układzie współrzędnych z metryką euklidesową gradient, jeśli istnieje, jest określony wzorem:

gdzie i , j , k są standardowymi wektorami jednostkowymi w kierunkach odpowiednio x , y i z . Na przykład gradient funkcji

jest

W niektórych zastosowaniach zwyczajowo przedstawia się gradient jako wektor wierszowy lub wektor kolumnowy jego składowych w prostokątnym układzie współrzędnych; ten artykuł jest zgodny z konwencją gradientu będącego wektorem kolumnowym, podczas gdy pochodna jest wektorem wierszowym.
Współrzędne cylindryczne i sferyczne
We współrzędnych cylindrycznych z metryką euklidesową gradient wyraża się wzorem:

gdzie ρ jest odległość osiowa φ jest azymutu i kąta azymutu, z jest współrzędną osiowe i e ρ , e φ i e z wektory jednostki wskazujące wzdłuż współrzędnych kierunkach.
We współrzędnych sferycznych gradient wyraża się wzorem:

gdzie R oznacza odległość promieniową, φ jest kąt kierunkowy i θ jest kątowa i e r , e θ i e φ znowu miejsca wektor jednostkowy zwróconą w kierunku koordynacji (to znaczy znormalizowana bazowych kowariantna ).
Aby zapoznać się z gradientem w innych ortogonalnych układach współrzędnych , zobacz Współrzędne ortogonalne (Operatory różniczkowe w trzech wymiarach) .
Współrzędne ogólne
Rozważamy współrzędne ogólne , które zapisujemy jako x 1 , …, x i , …, x n , gdzie n jest liczbą wymiarów dziedziny. W tym przypadku górny indeks odnosi się do pozycji na liście współrzędnych lub składnika, więc x 2 odnosi się do drugiego składnika, a nie do ilości x do kwadratu. Zmienna indeksująca i odnosi się do dowolnego elementu x i . Używając notacji Einsteina , gradient można następnie zapisać jako:
- (Zauważ, że jego podwójna jest ),


gdzie i odnoszą się odpowiednio do nieznormalizowanych lokalnych zasad kowariantnych i kontrawariantnych , jest tensorem metryki odwrotnej , a konwencja sumowania Einsteina implikuje sumowanie przez i oraz j .



Jeśli współrzędne są ortogonalne, możemy łatwo wyrazić gradient (i różniczkę ) w postaci znormalizowanych baz, które nazywamy i , używając współczynników skali (znanych również jako współczynniki Lamé ) :



- ( i ),


gdzie nie możemy użyć notacji Einsteina, ponieważ nie da się uniknąć powtórzenia więcej niż dwóch indeksów. Pomimo zastosowania górnych i dolnych indeksów , , i nie są ani kontrawariantne, ani kowariantne.



To ostatnie wyrażenie daje w wyniku wyrażenia podane powyżej dla współrzędnych cylindrycznych i sferycznych.
Związek z pochodną
| Część serii artykułów o |
| Rachunek różniczkowy |
|---|
Związek z całkowitą pochodną
Gradient jest ściśle powiązany z pochodną całkowitą ( różnicką całkowitą ) : są one transponowane ( podwójne ) do siebie. Stosując konwencję, że wektory w są reprezentowane przez wektory kolumnowe , a kowektory (mapy liniowe ) są reprezentowane przez wektory wierszowe , gradient i pochodna są wyrażane odpowiednio jako wektor kolumnowy i wierszowy, z tymi samymi składnikami, ale transponują każdy z nich inny:




Chociaż oba mają te same składniki, różnią się rodzajem obiektu matematycznego, który reprezentują: w każdym punkcie pochodną jest wektor kostyczny , forma liniowa ( covector ), która wyraża, jak bardzo (skalarny) zmienia się wynik dla danej nieskończenie małej zmiana wejścia (wektorowego), podczas gdy w każdym punkcie gradient jest wektorem stycznym , który reprezentuje nieskończenie małą zmianę wejścia (wektorowego). W symbolach gradient jest elementem przestrzeni stycznej w punkcie , natomiast pochodna jest odwzorowaniem przestrzeni stycznej na liczby rzeczywiste , . Przestrzenie styczne w każdym punkcie można „naturalnie” utożsamić z samą przestrzenią wektorową i podobnie przestrzeń kostyczną w każdym punkcie można naturalnie utożsamić z podwójną przestrzenią wektorową kowektorów; w ten sposób wartość gradientu w punkcie można traktować jako wektor w oryginale , a nie tylko jako wektor styczny.



Obliczeniowo, mając wektor styczny, wektor można pomnożyć przez pochodną (jako macierze), co jest równe pobraniu iloczynu skalarnego z gradientem:

Różniczka lub (zewnętrzna) pochodna
Najlepsze przybliżenie liniowe do funkcji różniczkowalnej
w punkcie X, w R n jest liniowym z R N do B , który jest często oznaczany przez df X lub Df ( x ) i zwany różnicowy lub całkowitą pochodną o f w x . Funkcja DF , który odwzorowuje x do DF x jest nazywany całkowitej różnicy lub zewnętrzne pochodną o f i jest przykładem różnicowego 1-formy .
Podobnie jak pochodna funkcji jednej zmiennej oznacza nachylenie na stycznej do wykresu funkcji kierunkowa pochodną funkcją wielu zmiennych oznacza nachylenie stycznej hiperpłaszczyznę w kierunku wektora.
Gradient jest powiązany z różniczką wzorem

dla dowolnego v ∈ R n , gdzie jest iloczynem skalarnym : pobranie iloczynu skalarnego wektora z gradientem jest takie samo, jak pobranie pochodnej kierunkowej wzdłuż wektora.

Jeżeli R n jest postrzegane jako przestrzeń (wymiar n ) wektorów kolumnowych (liczb rzeczywistych), to df można traktować jako wektor wierszowy ze składowymi

tak, że df x ( v ) jest dane przez mnożenie macierzy . Zakładając standardową metrykę euklidesową na R n , gradient jest wtedy odpowiednim wektorem kolumnowym, to znaczy

Aproksymacja liniowa do funkcji
Najlepsze przybliżenie liniowe funkcji można wyrazić w postaci gradientu, a nie pochodnej. Gradient funkcji f z przestrzeni euklidesowej R n do R w dowolnym punkcie x 0 w R n charakteryzuje najlepsze przybliżenie liniowe do f w x 0 . Przybliżenie jest następujące:

dla x blisko x 0 , gdzie (∇ f ) x 0 jest gradientem f obliczonym w x 0 , a kropka oznacza iloczyn skalarny na R n . To równanie jest równoważne pierwszym dwóm członom w wielowymiarowym rozwinięciu f w szeregu Taylora w punkcie x 0 .
Związek z pochodną Fréchet
Niech U będzie zbiorem otwartym w R n . Jeżeli funkcja F : U → R jest różniczkowalną, wówczas różniczka f jest pochodna Fréchet z F . Zatem ∇ f jest funkcją od U do przestrzeni R n taką, że

gdzie · jest iloczynem skalarnym.
W konsekwencji, zwykłe własności pochodnej obowiązują dla gradientu, chociaż gradient nie jest sam w sobie pochodną, ale raczej dualną do pochodnej:
Gradient jest liniowy w tym sensie, że jeśli f i g są dwiema funkcjami o wartościach rzeczywistych, różniczkowalnymi w punkcie a ∈ R n , a α i β są dwiema stałymi, to αf + βg jest różniczkowalna w a , a ponadto

Jeśli f i g są funkcjami o wartościach rzeczywistych różniczkowalnymi w punkcie a ∈ R n , to reguła iloczynu zakłada, że iloczyn fg jest różniczkowalny w a , oraz

Załóżmy, że f : A → R jest funkcją o wartościach rzeczywistych zdefiniowaną na podzbiorze A z R n , oraz że f jest różniczkowalna w punkcie a . Istnieją dwie formy reguły łańcucha mającej zastosowanie do gradientu. Najpierw załóżmy, że funkcja g jest krzywą parametryczną ; czyli funkcja g : I → R n odwzorowuje podzbiór I ⊂ R na R n . Jeśli g jest różniczkowalna w punkcie c ∈ I takim, że g ( c ) = a , wtedy

gdzie ∘ jest operatorem kompozycji : ( f ∘ g ) ( x ) = f ( g ( x ) ) .
Bardziej ogólnie, jeśli zamiast tego I ⊂ R k , to zachodzi:

gdzie ( Dg ) T oznacza transponowaną macierz Jakobianu .
Dla drugiej postaci reguły łańcucha załóżmy, że h : I → R jest funkcją o wartościach rzeczywistych na podzbiorze I z R , i że h jest różniczkowalna w punkcie f ( a ) ∈ I . Następnie

Dalsze właściwości i zastosowania
Zestawy poziomów
Powierzchnia pozioma lub izopowierzchnia to zbiór wszystkich punktów, w których jakaś funkcja ma określoną wartość.
Jeśli f jest różniczkowalne, to iloczyn skalarny (∇ f ) x ⋅ v gradientu w punkcie x z wektorem v daje pochodną kierunkową f w x w kierunku v . Wynika z tego, że w tym przypadku, gradient F jest prostopadły do zestawów poziomu o f . Na przykład płaska powierzchnia w przestrzeni trójwymiarowej jest zdefiniowana równaniem postaci F ( x , y , z ) = c . Gradient F jest wtedy normalny do powierzchni.
Bardziej ogólnie, każda osadzona hiperpowierzchnia w rozmaitości Riemanna może być wycinana równaniem postaci F ( P )=0 tak, że dF nie jest nigdzie zerem. Gradient F jest wtedy normalny do hiperpowierzchni.
Podobnie, afiniczny algebraiczna hiperpowierzchni mogą być zdefiniowane za pomocą równania F ( x 1 , ..., x n ) = 0 , gdzie K jest wielomianem. Gradient F wynosi zero w punkcie osobliwym hiperpowierzchni (jest to definicja punktu osobliwego). W punkcie nieosobliwym jest to niezerowy wektor normalny.
Konserwatywne pola wektorowe i twierdzenie o gradiencie
Gradient funkcji nazywany jest polem gradientowym. Pole gradientu (ciągłego) jest zawsze konserwatywnym polem wektorowym : jego całka krzywoliniowa wzdłuż dowolnej ścieżki zależy tylko od punktów końcowych ścieżki i może być oceniona przez twierdzenie gradientowe (podstawowe twierdzenie rachunku różniczkowego dla całek krzywoliniowych). I odwrotnie, (ciągłe) konserwatywne pole wektorowe jest zawsze gradientem funkcji.
Uogólnienia
Jakobian
Jakobian matryca jest uogólnieniem gradient funkcji wektora wartościach od kilku zmiennych różniczkowalnych mapy między euklidesowych , lub bardziej ogólnie, rozdzielaczy . Dalszym uogólnieniem funkcji między przestrzeniami Banacha jest pochodna Frécheta .
Załóżmy, że f : ℝ n → ℝ m jest funkcją taką, że każda z jej pochodnych cząstkowych pierwszego rzędu istnieje na ℝ n . Wtedy jakobian macierz f definiuje się jako macierz m × n , oznaczoną przez lub po prostu . ( I , j ) th wpisu . Jawnie




Gradient pola wektorowego
Ponieważ całkowita pochodna pola wektorowego jest odwzorowaniem liniowym z wektorów na wektory, jest to wielkość tensorowa .
We współrzędnych prostokątnych gradient pola wektorowego f = ( f 1 , f 2 , f 3 ) jest określony wzorem:

(gdzie zapis sumowanie Einsteina jest używany, a produkt napinacz wektorów e I a E K jest dwójkowym napinacz typu (2,0)). Ogólnie rzecz biorąc, wyrażenie to jest równe transpozycji macierzy Jakobianu:

We współrzędnych krzywoliniowych, lub bardziej ogólnie na zakrzywionej rozmaitości , gradient obejmuje symbole Christoffela :

gdzie g jk to składowe odwrotnego tensora metrycznego, a e i to wektory bazowe współrzędnych.
Wyrażony bardziej niezmiennie, gradient pola wektorowego f można zdefiniować za pomocą połączenia Levi-Civita i tensora metrycznego:

gdzie ∇ c jest połączeniem.
Rozmaitości riemannowskie
Dla dowolnej gładkiej funkcji f na rozmaitości Riemanna ( M , g ) gradient f jest polem wektorowym ∇ f takim, że dla dowolnego pola wektorowego X ,

to jest,

gdzie g x ( , ) oznacza iloczyn skalarny wektorów stycznych w x zdefiniowanym przez metrykę g , a ∂ X f jest funkcją, która przyjmuje dowolny punkt x ∈ M do kierunkowej pochodnej f w kierunku X , obliczonej w x . Innymi słowy, na wykresie współrzędnych φ od otwartego podzbioru M do otwartego podzbioru R n , (∂ X f )( x ) jest dane wzorem:

gdzie X j oznacza j- tą składową X na tym wykresie współrzędnych.
Tak więc lokalna forma gradientu przyjmuje postać:

Uogólniając przypadek M = R n , gradient funkcji jest powiązany z jej zewnętrzną pochodną, ponieważ

Dokładniej, gradient ∇ f jest polem wektorowym związanym z różniczkową 1-formą df przy użyciu izomorfizmu muzycznego

(nazywany „ostrym”) zdefiniowanym przez metrykę g . Związek między pochodną zewnętrzną a gradientem funkcji na R n jest szczególnym przypadkiem tego, w którym metryka jest metryką płaską podaną przez iloczyn skalarny.
Zobacz też
Uwagi
Bibliografia
- Bachman, David (2007), Advanced Calculus Demystified , New York: McGraw-Hill , ISBN 978-0-07-148121-2
- Beauregard, Raymond A.; Fraleigh, John B. (1973), Pierwszy kurs algebry liniowej: z opcjonalnym wprowadzeniem do grup, pierścieni i pól , Boston: Houghton Mifflin Company , ISBN 0-395-14017-X
- Downing, Douglas, Ph.D. (2010), Barron's EZ Calculus , New York: Barron's , ISBN 978-0-7641-4461-5
- Dubrowin, BA; Fomenko, AT; Nowikow SP (1991). Współczesna geometria — metody i zastosowania: Część I: Geometria powierzchni, grup transformacji i pól . Teksty magisterskie z matematyki (wyd. 2). Skoczek. Numer ISBN 978-0-387-97663-1.
- Harper, Charlie (1976), Wprowadzenie do fizyki matematycznej , New Jersey: Prentice-Hall , ISBN 0-13-487538-9
- Kreyszig, Erwin (1972), Advanced Engineering Mathematics (3rd ed.), New York: Wiley , ISBN 0-471-50728-8
- „McGraw Hill Encyklopedia Nauki i Technologii”. Encyklopedia Nauki i Technologii McGraw-Hill (wyd. 10). Nowy Jork: McGraw-Hill . 2007. ISBN 978-0-07-144143-8.
- Moise, Edwin E. (1967), Rachunek: Complete , Czytanie: Addison-Wesley
- Protter, Murray H.; Morrey, Jr., Charles B. (1970), College Rachunek z geometrią analityczną (2nd ed.), Czytanie: Addison-Wesley , LCCN 76087042
- Schey, HM (1992). Div, Grad, Curl i All That (wyd. 2). WW Norton. Numer ISBN 0-393-96251-2. OCLC 25048561 .
- Stoker, JJ (1969), Geometria różniczkowa , New York: Wiley , ISBN 0-471-82825-4
- Swokowski hrabia W.; Olinick, Michael; Pensa, Dennisa; Cole, Jeffery A. (1994), Rachunek (wyd. 6), Boston: PWS Publishing Company, ISBN 0-534-93624-5
Dalsza lektura
- Korn, Theresa M .; Korn, Granino Artur (2000). Podręcznik matematyczny dla naukowców i inżynierów: Definicje, twierdzenia i formuły odniesienia i przeglądu . Publikacje Dovera. s. 157–160. Numer ISBN 0-486-41147-8. OCLC 43864234 .
Zewnętrzne linki
- „Gradient” . Akademia Khana .
- Kuptsov, LP (2001) [1994], "Gradient" , Encyklopedia Matematyki , EMS Press.
- Weisstein, Eric W. „Gradient” . MatematykaŚwiat .