Type of artificial neural network that uses radial basis functions as activation functions
W dziedzinie modelowania matematycznego sieć radialnych funkcji bazowych jest sztuczną siecią neuronową, która wykorzystuje radialne funkcje bazowe jako funkcje aktywacji . Wyjście sieci jest liniową kombinacją radialnych funkcji bazowych wejść i parametrów neuronu. Sieci funkcji radialnych mają wiele zastosowań, w tym aproksymację funkcji , przewidywanie szeregów czasowych , klasyfikację i sterowanie systemem . Zostały one po raz pierwszy sformułowane w pracy z 1988 roku przez Broomheada i Lowe'a, badaczy z Royal Signals and Radar Establishment .
Architektura sieci

Architektura radialnej sieci funkcji bazowych. Wektor wejściowy jest używany jako dane wejściowe do wszystkich radialnych funkcji bazowych, z których każda ma inne parametry. Wyjście sieci jest liniową kombinacją wyjść z radialnych funkcji bazowych.

Sieci z promieniową funkcją bazową (RBF) zazwyczaj mają trzy warstwy: warstwę wejściową, warstwę ukrytą z nieliniową funkcją aktywacji RBF i liniową warstwę wyjściową. Wejście można zamodelować jako wektor liczb rzeczywistych . Wynikiem sieci jest wtedy funkcja skalarna wektora wejściowego , i jest dana wzorem



gdzie jest liczbą neuronów w warstwie ukrytej, jest wektorem środkowym dla neuronu i jest wagą neuronu w neuronie z wyjściem liniowym. Funkcje zależne tylko od odległości od wektora środkowego są promieniowo symetryczne względem tego wektora, stąd nazwa radialna funkcja bazowa. W podstawowej formie wszystkie wejścia są połączone z każdym ukrytym neuronem. Za normę zwykle przyjmuje się odległość euklidesową (chociaż odległość Mahalanobisa wydaje się działać lepiej z rozpoznawaniem wzorców), a promieniowa funkcja bazowa jest powszechnie uważana za Gaussa



-
![{\displaystyle \rho {\big (}\left\Vert \mathbf {x} -\mathbf {c} _{i}\right\Vert {\big )}=\exp \left[-\beta _{i}\left\Vert \mathbf {x} -\mathbf {c} _{i}\right\Vert ^{2}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/810b210447cf6a4e00b141425a5da1cf6cb3914c) .
.
Funkcje bazowe Gaussa są lokalne względem wektora środkowego w tym sensie, że

tzn. zmiana parametrów jednego neuronu ma niewielki wpływ na wartości wejściowe, które są daleko od centrum tego neuronu.
Biorąc pod uwagę pewne łagodne warunki dotyczące kształtu funkcji aktywacji, sieci RBF są uniwersalnymi aproksymatorami na zwartym podzbiorze . Oznacza to, że sieć RBF z wystarczającą liczbą ukrytych neuronów może aproksymować dowolną ciągłą funkcję na zamkniętym, ograniczonym zbiorze z dowolną precyzją.

Parametry , i są określane w sposób, który optymalizuje dopasowanie danych do danych.


Znormalizowane
Dwie znormalizowane promieniowe funkcje bazowe w jednym wymiarze wejściowym (
sigmoidy ). Podstawowe centra funkcyjne znajdują się pod adresem i .


Trzy znormalizowane promieniowe funkcje bazowe w jednym wymiarze wejściowym. Dodatkowa funkcja podstawowa ma centrum na

Cztery znormalizowane promieniowe funkcje bazowe w jednym wymiarze wejściowym. Czwarta funkcja bazowa ma centrum w . Zauważ, że pierwsza funkcja bazowa (kolor ciemnoniebieski) została zlokalizowana.

Znormalizowana architektura
Oprócz powyższej nieznormalizowanej architektury, sieci RBF mogą być znormalizowane . W tym przypadku mapowanie to

gdzie

jest znana jako znormalizowana radialna funkcja bazowa .
Teoretyczna motywacja do normalizacji
Istnieje teoretyczne uzasadnienie takiej architektury w przypadku stochastycznego przepływu danych. Załóż stochastyczne przybliżenie jądra dla łącznej gęstości prawdopodobieństwa

gdzie wagi i są przykładami z danych i wymagamy normalizacji jąder


i
-
 .
.
Gęstości prawdopodobieństwa w przestrzeniach wejściowych i wyjściowych wynoszą

i
Oczekiwanie y dla danych wejściowych to


gdzie

jest prawdopodobieństwem warunkowym danego y . Prawdopodobieństwo warunkowe jest powiązane z prawdopodobieństwem łącznym za pomocą twierdzenia Bayesa

co daje
-
 .
.
To staje się

kiedy wykonywane są integracje.
Lokalne modele liniowe
Czasami wygodnie jest rozszerzyć architekturę o lokalne modele liniowe . W takim przypadku architektury stają się, w pierwszej kolejności,

i

odpowiednio w przypadkach nieznormalizowanych i znormalizowanych. Oto wagi do ustalenia. Możliwe są również terminy liniowe wyższego rzędu.

Ten wynik można zapisać

gdzie
![e_{{ij}}={\begin{cases}a_{i},&{\mbox{if }}i\in [1,N]\\b_{{ij}},&{\mbox{if }}i\in [N+1,2N]\end{cases}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e69e7a0b20246396ad4ecf0619932d3818cb14fb)
i
![v_{{ij}}{\big (}{\mathbf {x}}-{\mathbf {c}}_{i}{\big )}\ {\stackrel {{\mathrm {def}}}{=}}\ {\begin{cases}\delta _{{ij}}\rho {\big (}\left\Vert {\mathbf {x}}-{\mathbf {c}}_{i}\right\Vert {\big )},&{\mbox{if }}i\in [1,N]\\\left(x_{{ij}}-c_{{ij}}\right)\rho {\big (}\left\Vert {\mathbf {x}}-{\mathbf {c}}_{i}\right\Vert {\big )},&{\mbox{if }}i\in [N+1,2N]\end{cases}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6194ed23e27bf63b899a072ce2803f31fba1f84)
w przypadku nieznormalizowanym i
![v_{{ij}}{\big (}{\mathbf {x}}-{\mathbf {c}}_{i}{\big )}\ {\stackrel {{\mathrm {def}}}{=}}\ {\begin{cases}\delta _{{ij}}u{\big (}\left\Vert {\mathbf {x}}-{\mathbf {c}}_{i}\right\Vert {\big )},&{\mbox{if }}i\in [1,N]\\\left(x_{{ij}}-c_{{ij}}\right)u{\big (}\left\Vert {\mathbf {x}}-{\mathbf {c}}_{i}\right\Vert {\big )},&{\mbox{if }}i\in [N+1,2N]\end{cases}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0f7d20e63f94b312d972d1c925a999de68c68735)
w znormalizowanym przypadku.
Tutaj jest funkcją Kronecker delta określa się jako

-
 .
.
Trening
Sieci RBF są zazwyczaj trenowane z par wartości wejściowych i docelowych , za pomocą dwuetapowego algorytmu.


W pierwszym kroku wybierane są środkowe wektory funkcji RBF w warstwie ukrytej. Ten krok można wykonać na kilka sposobów; centra mogą być losowo wybrane z pewnego zestawu przykładów lub można je określić za pomocą grupowania k-średnich . Zauważ, że ten krok nie jest nadzorowany .
Drugi krok po prostu dopasowuje model liniowy ze współczynnikami do wyników ukrytej warstwy w odniesieniu do jakiejś funkcji celu. Wspólną funkcją celu, przynajmniej dla estymacji regresji/funkcji, jest funkcja najmniejszych kwadratów:


gdzie
-
![K_{t}({\mathbf {w}})\ {\stackrel {{\mathrm {def}}}{=}}\ {\big [}y(t)-\varphi {\big (}{\mathbf {x}}(t),{\mathbf {w}}{\big )}{\big ]}^{2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/47c25fbbbb15c069216597e2a3489f0c7ba6ac62) .
.
Wyraźnie uwzględniliśmy zależność od wag. Minimalizacja funkcji celu najmniejszych kwadratów poprzez optymalny dobór wag optymalizuje dokładność dopasowania.
Są sytuacje, w których należy zoptymalizować wiele celów, takich jak płynność i dokładność. W takim przypadku warto zoptymalizować uregulowaną funkcję celu, taką jak

gdzie

i

gdzie optymalizacja S maksymalizuje gładkość i jest znana jako parametr regularyzacji .

Trzeci opcjonalny krok wstecznej propagacji może być wykonany w celu dokładnego dostrojenia wszystkich parametrów sieci RBF.
Interpolacja
Sieci RBF mogą być użyte do interpolacji funkcji, gdy wartości tej funkcji są znane na skończonej liczbie punktów: . Biorąc znane punkty jako środki radialnych funkcji bazowych i obliczając wartości funkcji bazowych w tych samych punktach wagi można rozwiązać z równania




![\left[{\begin{matrix}g_{{11}}&g_{{12}}&\cdots &g_{{1N}}\\g_{{21}}&g_{{22}}&\cdots &g_{{2N}}\\\vdots &&\ddots &\vdots \\g_{{N1}}&g_{{N2}}&\cdots &g_{{NN}}\end{matrix}}\right]\left[{\begin{matrix}w_{1}\\w_{2}\\\vdots \\w_{N}\end{matrix}}\right]=\left[{\begin{matrix}b_{1}\\b_{2}\\\vdots \\b_{N}\end{matrix}}\right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a4456b5dd861c3af9665875ed2e674003029074)
Można wykazać, że macierz interpolacji w powyższym równaniu jest nieosobliwa, jeśli punkty są różne, a zatem wagi można rozwiązać za pomocą prostej algebry liniowej:


gdzie .

Przybliżenie funkcji
Jeśli celem nie jest wykonanie ścisłej interpolacji, ale bardziej ogólne przybliżenie funkcji lub klasyfikacja, optymalizacja jest nieco bardziej złożona, ponieważ nie ma oczywistego wyboru dla centrów. Trening odbywa się zazwyczaj w dwóch fazach, najpierw ustalając szerokość i środki, a następnie ciężary. Można to uzasadnić, biorąc pod uwagę różną naturę nieliniowych ukrytych neuronów w porównaniu z liniowym neuronem wyjściowym.
Szkolenie podstawowych ośrodków funkcyjnych
Centra funkcji bazowych mogą być losowo próbkowane spośród wystąpień wejściowych lub uzyskane za pomocą algorytmu uczenia ortogonalnego najmniejszych kwadratów lub znalezione przez grupowanie próbek i wybieranie średnich skupień jako centrów.
Szerokości RBF są zwykle ustawione na taką samą wartość, która jest proporcjonalna do maksymalnej odległości między wybranymi środkami.
Pseudoodwrotne rozwiązanie dla wag liniowych
Po ustaleniu środków wagi, które minimalizują błąd na wyjściu, można obliczyć za pomocą liniowego rozwiązania pseudoodwrotnego :

-
 ,
,
gdzie wpisy G są wartościami radialnych funkcji bazowych obliczonych w punktach : .


Istnienie tego liniowego rozwiązania oznacza, że w przeciwieństwie do wielowarstwowych sieci perceptronowych (MLP), sieci RBF mają wyraźny minimalizator (gdy centra są ustalone).
Gradientowy trening z ciężarami liniowymi
Innym możliwym algorytmem uczącym jest zejście gradientowe . W treningu zejścia w gradiencie, ciężary są korygowane w każdym kroku, przesuwając je w kierunku przeciwnym do gradientu funkcji celu (co pozwala na znalezienie minimum funkcji celu),

gdzie jest „parametrem uczenia się”.

W przypadku uczenia wag liniowych , algorytm przyjmuje postać
![a_{i}(t+1)=a_{i}(t)+\nu {\big [}y(t)-\varphi {\big (}{\mathbf {x}}(t),{\mathbf {w}}{\big )}{\big ]}\rho {\big (}\left\Vert {\mathbf {x}}(t)-{\mathbf {c}}_{i}\right\Vert {\big )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d6ff0ca244dbf79403808304d1970f20cee63383)
w przypadku nieznormalizowanym i
![a_{i}(t+1)=a_{i}(t)+\nu {\big [}y(t)-\varphi {\big (}{\mathbf {x}}(t),{\mathbf {w}}{\big )}{\big ]}u{\big (}\left\Vert {\mathbf {x}}(t)-{\mathbf {c}}_{i}\right\Vert {\big )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/30d53a925c043711f42e74be811973f9c14563ea)
w znormalizowanym przypadku.
W przypadku lokalnych architektur liniowych trening z gradientem to
![e_{{ij}}(t+1)=e_{{ij}}(t)+\nu {\big [}y(t)-\varphi {\big (}{\mathbf {x}}(t),{\mathbf {w}}{\big )}{\big ]}v_{{ij}}{\big (}{\mathbf {x}}(t)-{\mathbf {c}}_{i}{\big )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6ed23c9f1311d7090b1f9354acd1ea651133e87b)
Szkolenie operatora projekcji ciężarów liniowych
W przypadku uczenia wag liniowych i , algorytm staje się

![a_{i}(t+1)=a_{i}(t)+\nu {\big [}y(t)-\varphi {\big (}{\mathbf {x}}(t),{\mathbf {w}}{\big )}{\big ]}{\frac {\rho {\big (}\left\Vert {\mathbf {x}}(t)-{\mathbf {c}}_{i}\right\Vert {\big )}}{\sum _{{i=1}}^{N}\rho ^{2}{\big (}\left\Vert {\mathbf {x}}(t)-{\mathbf {c}}_{i}\right\Vert {\big )}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/daada7fa66c0c152fa6ddbe9b4688bab0e069771)
w przypadku nieznormalizowanym i
![a_{i}(t+1)=a_{i}(t)+\nu {\big [}y(t)-\varphi {\big (}{\mathbf {x}}(t),{\mathbf {w}}{\big )}{\big ]}{\frac {u{\big (}\left\Vert {\mathbf {x}}(t)-{\mathbf {c}}_{i}\right\Vert {\big )}}{\sum _{{i=1}}^{N}u^{2}{\big (}\left\Vert {\mathbf {x}}(t)-{\mathbf {c}}_{i}\right\Vert {\big )}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ded07d14fa15e102334231468d90bc62d88fba0e)
w znormalizowanym przypadku i
![e_{{ij}}(t+1)=e_{{ij}}(t)+\nu {\big [}y(t)-\varphi {\big (}{\mathbf {x}}(t),{\mathbf {w}}{\big )}{\big ]}{\frac {v_{{ij}}{\big (}{\mathbf {x}}(t)-{\mathbf {c}}_{i}{\big )}}{\sum _{{i=1}}^{N}\sum _{{j=1}}^{n}v_{{ij}}^{2}{\big (}{\mathbf {x}}(t)-{\mathbf {c}}_{i}{\big )}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ca63b9d8b8402fb255847feee9f93cbedcfd71bd)
w przypadku lokalno-liniowym.
Dla jednej podstawowej funkcji, szkolenie operatora projekcji sprowadza się do metody Newtona .

Rysunek 6: Szeregi czasowe mapy logistycznej. Wielokrotna iteracja mapy logistycznej generuje chaotyczny szereg czasowy. Wartości mieszczą się w zakresie od zera do jednego. Wyświetlanych jest tutaj 100 punktów treningowych użytych do trenowania przykładów w tej sekcji. Wagi c to pierwsze pięć punktów z tego szeregu czasowego.
Przykłady
Mapa logistyczna
Podstawowe własności radialnych funkcji bazowych można zilustrować prostą mapą matematyczną, mapą logistyczną , która odwzorowuje na siebie przedział jednostkowy. Może być używany do generowania wygodnego prototypowego strumienia danych. Mapa logistyczna może być wykorzystana do badania aproksymacji funkcji , przewidywania szeregów czasowych i teorii sterowania . Mapa wywodzi się z dziedziny dynamiki populacji i stała się prototypem chaotycznych szeregów czasowych. Mapę, w całkowicie chaotycznym reżimie, podaje
![x(t+1)\ {\stackrel {{\mathrm {def}}}{=}}\ f\left[x(t)\right]=4x(t)\left[1-x(t)\right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/d18e751a88c7fd2ac285b21f9c567db55c214e97)
gdzie t jest indeksem czasu. Wartość x w czasie t+1 jest funkcją paraboliczną x w czasie t. To równanie reprezentuje podstawową geometrię chaotycznego szeregu czasowego generowanego przez mapę logistyczną.
Generowanie szeregów czasowych z tego równania jest problemem postępującym . Poniższe przykłady ilustrują problem odwrotny ; identyfikacja podstawowej dynamiki lub fundamentalnego równania mapy logistycznej z przykładowych szeregów czasowych. Celem jest znalezienie oszacowania
![x(t+1)=f\left[x(t)\right]\approx \varphi (t)=\varphi \left[x(t)\right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/db59ba99d8c9e0d2e5d34cae9692a5f3a22cf33b)
dla fa.
Przybliżenie funkcji
Nieznormalizowane promieniowe funkcje bazowe
Architektura jest
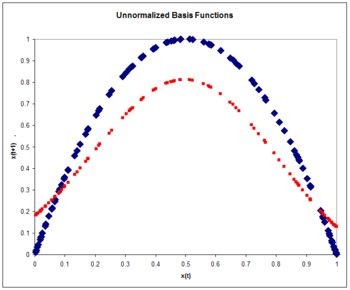
Rysunek 7: Nieznormalizowane funkcje bazowe. Mapa logistyczna (kolor niebieski) i przybliżenie do mapy logistycznej (kolor czerwony) po jednym przejściu przez zbiór uczący.

gdzie
-
![{\displaystyle \rho {\big (}\left\Vert \mathbf {x} -\mathbf {c} _{i}\right\Vert {\big )}=\exp \left[-\beta _{i}\left\Vert \mathbf {x} -\mathbf {c} _{i}\right\Vert ^{2}\right]=\exp \left[-\beta _{i}\left(x(t)-c_{i}\right)^{2}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/25c7d4d37abe3b8601a437cb4769cddc6cf3833e) .
.
Ponieważ dane wejściowe są skalarem, a nie wektorem , wymiar wejściowy jest jeden. Wybieramy liczbę funkcji bazowych jako N=5 i wielkość zbioru treningowego na 100 przykładów generowanych przez chaotyczne szeregi czasowe. Za wagę przyjmuje się stałą równą 5. Wagi stanowią pięć przykładów z szeregu czasowego. Wagi są szkolone ze szkoleniem operatora projekcji:

![a_{i}(t+1)=a_{i}(t)+\nu {\big [}x(t+1)-\varphi {\big (}{\mathbf {x}}(t),{\mathbf {w}}{\big )}{\big ]}{\frac {\rho {\big (}\left\Vert {\mathbf {x}}(t)-{\mathbf {c}}_{i}\right\Vert {\big )}}{\sum _{{i=1}}^{N}\rho ^{2}{\big (}\left\Vert {\mathbf {x}}(t)-{\mathbf {c}}_{i}\right\Vert {\big )}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d4fce40bfbe9b946581809f2a627f174aaf33c64)
gdzie współczynnik uczenia się wynosi 0,3. Trening odbywa się przy jednym przejściu przez 100 punktów treningowych. Błąd RMS wynosi 0,15.
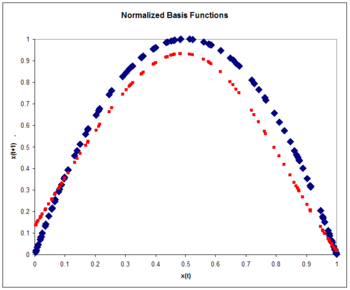
Rysunek 8: Znormalizowane funkcje bazowe. Mapa logistyczna (kolor niebieski) i przybliżenie do mapy logistycznej (kolor czerwony) po jednym przejściu przez zbiór uczący. Zwróć uwagę na poprawę w stosunku do przypadku nieznormalizowanego.
Znormalizowane promieniowe funkcje bazowe
Znormalizowana architektura RBF to
gdzie
-
 .
.
Jeszcze raz:
-
![\rho {\big (}\left\Vert {\mathbf {x}}-{\mathbf {c}}_{i}\right\Vert {\big )}=\exp \left[-\beta \left\Vert {\mathbf {x}}-{\mathbf {c}}_{i}\right\Vert ^{2}\right]=\exp \left[-\beta \left(x(t)-c_{i}\right)^{2}\right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/b386dbd43b5eb5df76b52f6e6214f2b4339d4dae) .
.
Ponownie wybieramy liczbę funkcji bazowych na pięć i wielkość zbioru treningowego na 100 przykładów wygenerowanych przez chaotyczne szeregi czasowe. Za wagę przyjmuje się stałą równą 6. Wagi stanowią pięć przykładów z szeregu czasowego. Ciężary są szkolone ze szkoleniem operatora projekcji:
![a_{i}(t+1)=a_{i}(t)+\nu {\big [}x(t+1)-\varphi {\big (}{\mathbf {x}}(t),{\mathbf {w}}{\big )}{\big ]}{\frac {u{\big (}\left\Vert {\mathbf {x}}(t)-{\mathbf {c}}_{i}\right\Vert {\big )}}{\sum _{{i=1}}^{N}u^{2}{\big (}\left\Vert {\mathbf {x}}(t)-{\mathbf {c}}_{i}\right\Vert {\big )}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be34ccc983222e1bbeb72d63eab95e64393dceb0)
gdzie współczynnik uczenia się ponownie przyjmuje się za 0,3. Trening odbywa się przy jednym przejściu przez 100 punktów treningowych. Błąd RMS na zestawie testowym 100 egzemplarzy wynosi 0,084, mniejszy niż nieznormalizowanych błędu. Normalizacja zapewnia poprawę dokładności. Zazwyczaj dokładność ze znormalizowanymi funkcjami bazowymi wzrasta jeszcze bardziej w porównaniu z funkcjami nieznormalizowanymi wraz ze wzrostem wymiaru wejściowego.

Rysunek 9: Znormalizowane funkcje bazowe. Mapa logistyczna (kolor niebieski) i aproksymacja mapy logistycznej (kolor czerwony) w funkcji czasu. Zauważ, że przybliżenie jest dobre tylko dla kilku kroków czasowych. Jest to ogólna charakterystyka chaotycznych szeregów czasowych.
Przewidywanie szeregów czasowych
Po oszacowaniu podstawowej geometrii szeregu czasowego, jak w poprzednich przykładach, prognozę dla szeregu czasowego można wykonać za pomocą iteracji:


-
![{x}(t+1)\approx \varphi (t)=\varphi [\varphi (t-1)]](https://wikimedia.org/api/rest_v1/media/math/render/svg/8ebe0e8d1ef472dc874ee8861bb9968afe83ad5a) .
.
Na rysunku przedstawiono porównanie rzeczywistych i szacowanych szeregów czasowych. Szacowane szeregi czasowe rozpoczynają się w czasie zero z dokładną wiedzą o x(0). Następnie wykorzystuje oszacowanie dynamiki do aktualizacji oszacowania szeregu czasowego dla kilku przedziałów czasowych.
Pamiętaj, że oszacowanie jest dokładne tylko dla kilku kroków czasowych. Jest to ogólna charakterystyka chaotycznych szeregów czasowych. Jest to właściwość wrażliwej zależności od warunków początkowych wspólnych dla chaotycznych szeregów czasowych. Mały początkowy błąd jest z czasem wzmacniany. Miarą rozbieżności szeregów czasowych o niemal identycznych warunkach początkowych jest wykładnik Lapunowa .
Kontrola chaotycznych szeregów czasowych

Rysunek 10: Kontrola mapy logistycznej. System może ewoluować naturalnie w 49 krokach czasowych. W momencie 50 sterowanie jest włączone. Żądana trajektoria dla szeregu czasowego jest czerwona. Kontrolowany system uczy się podstawowej dynamiki i kieruje szeregi czasowe do pożądanego wyniku. Architektura jest taka sama, jak w przykładzie przewidywania szeregów czasowych.
Zakładamy, że wyjściem mapy logistycznej można manipulować za pomocą parametru kontrolnego takiego, że
![c[x(t),t]](https://wikimedia.org/api/rest_v1/media/math/render/svg/a43de76171d5e934b86617d2c4f31173f85f1943)
-
![{x}_{{}}^{{}}(t+1)=4x(t)[1-x(t)]+c[x(t),t]](https://wikimedia.org/api/rest_v1/media/math/render/svg/ff5cb6dda1ba3c7e3514d4472f64c4b2cd1ab18f) .
.
Celem jest taki dobór parametru kontrolnego, aby doprowadzić szereg czasowy do pożądanej wartości wyjściowej . Można to zrobić, jeśli wybierzemy parametr kontrolny, który ma być

![c_{{}}^{{}}[x(t),t]\ {\stackrel {{\mathrm {def}}}{=}}\ -\varphi [x(t)]+d(t+1)](https://wikimedia.org/api/rest_v1/media/math/render/svg/e75069785f599ea18ae354ac38e34f625816011a)
gdzie
![y[x(t)]\approx f[x(t)]=x(t+1)-c[x(t),t]](https://wikimedia.org/api/rest_v1/media/math/render/svg/398cd41f2ca68133f79c5f62a81068049fca98b8)
jest przybliżeniem do podstawowej naturalnej dynamiki systemu.
Algorytm uczenia jest podany przez

gdzie
-
![\varepsilon \ {\stackrel {{\mathrm {def}}}{=}}\ f[x(t)]-\varphi [x(t)]=x(t+1)-c[x(t),t]-\varphi [x(t)]=x(t+1)-d(t+1)](https://wikimedia.org/api/rest_v1/media/math/render/svg/6acad5ff76bdcad25bf1beb62674724290392c10) .
.
Zobacz też
Bibliografia
Dalsza lektura
- J. Moody i CJ Darken, „Szybkie uczenie się w sieciach lokalnie dostrojonych jednostek przetwarzania”, Neural Computation, 1, 281-294 (1989). Zobacz także Radialne sieci funkcyjne według Moody i Darken
- T. Poggio i F. Girosi, „ Sieci dla aproksymacji i uczenia się ”, Proc. IEEE 78(9), 1484-1487 (1990).
-
Roger D. Jones , YC Lee, CW Barnes, GW Flake, K. Lee, PS Lewis i S. Qian, ? Aproksymacja funkcji i przewidywanie szeregów czasowych za pomocą sieci neuronowych ,? Proceedings of the International Joint Conference on Neural Networks, 17–21 czerwca, s. I-649 (1990).
-
Martina D. Buhmanna (2003). Radialne funkcje bazowe: teoria i implementacje . Uniwersytet Cambridge. Numer ISBN 0-521-63338-9.
-
Yee, Paul V. i Haykin, Simon (2001). Uregulowane sieci funkcji radialnych: teoria i zastosowania . Johna Wileya. Numer ISBN 0-471-35349-3.
- John R. Davies, Stephen V. Coggeshall, Roger D. Jones i Daniel Schutzer, „Inteligentne systemy bezpieczeństwa”, w: Freedman, Roy S., Flein, Robert A. i Lederman, Jess, Editors (1995). Sztuczna inteligencja na rynkach kapitałowych . Chicago: Irwin. Numer ISBN 1-55738-811-3.CS1 maint: multiple names: authors list (link)
-
Szymona Haykina (1999). Sieci neuronowe: kompleksowa podstawa (2nd ed.). Upper Saddle River, NJ: Prentice Hall. Numer ISBN 0-13-908385-5.
- S. Chen, CFN Cowan i PM Grant, „ Algorytm uczenia ortogonalnego najmniejszych kwadratów dla sieci z funkcją podstawy promieniowej ”, IEEE Transactions on Neural Networks, tom 2, nr 2 (marzec) 1991.










